![]()
Many, many new resources opening with the venerable LANDSAT 9 Project –LINK–

The Government of Canada (GC) recently published a broad strategy overview on the topic of satellite Earth Observation. The document -LINK- is public-facing and emphasizes the “three-Rs” of Resourceful Resilient Ready; a companion document not reviewed here, is written from a National Defence (sic) point of view, called Strong Secure Engaged. This pair, Defense and Sustainability, appear frequently in national strategy documents in the age of Climate Change.

This twenty page document, filled with impressive color photos of the world as viewed from above, is indeed a “green” document and contains many themes familiar in the broad sustainability movement and its vocabulary. The phrase Open Data is mentioned several times, but the acronym FAIR, common in academic circles, does not appear. Ironically, this document gives some passing support to the “economic value of open data” yet recently in the United States under the previous Presidency, weather data, EPA publications and most anything to do with Climate was made drastically less public, while engaging private business partnerships, allegedly to make better use of the resources. This Canadian GC document mentioned the European Union several times, but seldom the USA, its geographic neighbor and long-term military partner. Also new to me was the English-only presentation. The few GC documents I had reviewed in the past always had French language prominently along with English.
When remote sensing and Climate are the topic, flooding and sea level are always included, and this document is no exception. Flood and coastline analysis in remote sensing is a specialty, and I won’t be including much on that here. Another obvious aspect of remote sensing in Canada is that Canada is massive, complex and difficult to map for many reasons. If anyone needs remote sensing from satellites, it is Canada. In fact, we are informed that historically, Canada was the third nation in the world to operate satellites, presumably after the USA and USSR, in the early 1960s. Canada is part of the Arctic Council today, where some members are active competitors for natural resources and shipping. In plain talk, remote sensing has been used from the beginning to watch and measure the economic activity of competitors, and that remains a reliable revenue stream for this expensive endeavor to this day. Included here are details on some important and ongoing environmental sensor missions, including ozone layer and greenhouse gas monitoring, now more important than ever.
Glossy diagrams allegedly showing the benefits of alliance between Academic, Industry and Government programs, appeared to be shallow and relatively low-quality contributions, included for the positive message perhaps, but lacking important details and over-simplifying real life activity, effects and reach of these constantly changing partnerships. The document is an overview and is somewhat lacking in hard facts, other than the existence of showcased sensor satellite missions. Like similar green documents from California, a partnership with First Nations is extensively featured in one section, including education and training for traditionally underserved communities.
From the technology side, one might split topics between “Industry Support” and “Health & Safety.” Industry meaning existing economic activity, agriculture, resources flows, effects on jobs and the like, with Health and Safety including government functions like the monitoring of pest-born disease, water quality, and wildfires. None of these topics are new, especially in light of Canada being an early space pioneer, but the rate, quality and handling of satellite-based remote sensing data is new. Over the decades, it has to be said that previous specialized heavyweights such as High Performance Computing (HPC) have been eclipsed and I would say even embarrassed by the sheer capacity of Google, and more recently Amazon Web Services cloud computing. Despite public posturing, it is rumored that even the European Union Space Agency (ESA) itself uses AWS behind the scenes for its cost and performance. Google, AWS and others have routinely implemented Machine Learning systems on data flows for commercial purposes, techniques that remain mysterious and out of reach today even for established and well-connected companies and government. The ill-defined and somedays dubious term Artificial Intelligence appears in many consumer-oriented marketing material and the buzzwords of business plan promotion, but it is safe to say that we are in early days there still.
Wrapping up, it could be said that we are living in an AWS, post-Google world now, with cloud computing backends for exponentially increasing volumes of remote sensing data. Most advanced nations are promoting high tech for competitive reasons, and the Government of Canada presents its case here.
![]() Big Data and Artificial Intelligence for Earth Observation (EO)
Big Data and Artificial Intelligence for Earth Observation (EO)
19-20 November 2020, European Commission workshop
The two-day workshop presented nine research projects on big data and artificial intelligence for Copernicus and Earth Observation, funded under the Horizon 2020 Space Programme.
European Union’s Earth Observation Programme
The results of the five projects selected under the topic ‘EO-2-2017: EO Big Data Shift’.
The workshop introduced three new projects selected under the topic DT-SPACE-25-EO-2020: Big data technologies and Artificial Intelligence for Copernicus. Additionally, there will be one project selected under the topic LC-SPACE-18-EO-2020 Copernicus evolution: Research activities in support of the evolution of the Copernicus services subtopic Copernicus Land Monitoring Service.
Innovative EO solutions that the projects have developed:
* OpenEO [LINK]
* the CANDELA platform [LINK] [YOUTUBE]
* EO-LEARN PerceptiveSentinel’s Python library [LINK]
* Sentinel Hub [LINK]
* the EOPEN platform [LINK]
* the BETTER Data Pipelines [LINK] [HACK]
New projects:
* CALLISTO mobile/secure Big Data platform
* the DeepCube Platform for analytics and AI
* GEM’s AI-enhanced EO-LEARN framework [TWITTER]
* RapidAI4EO [LINK] improved AI land monitoring applications
UPDATE 2022
YNews user tehCorner writes:
My first job was in a company fully dedicated to milk the European H2020 projects’ cow. Their business model was to offer the lowest budget on a series of projects and then have a bunch of interns like me do all the work on their own with very bad conditions (very few were actually even paid and we didn’t have right for holidays).
At some point we all realized the profit the company was making with us and demanded better conditions, they rejected our claims and we planned to leave all at time they had to deliver the projects and get paid. Nothing got delivered, they didn’t get paid and just went out of business.
![]()
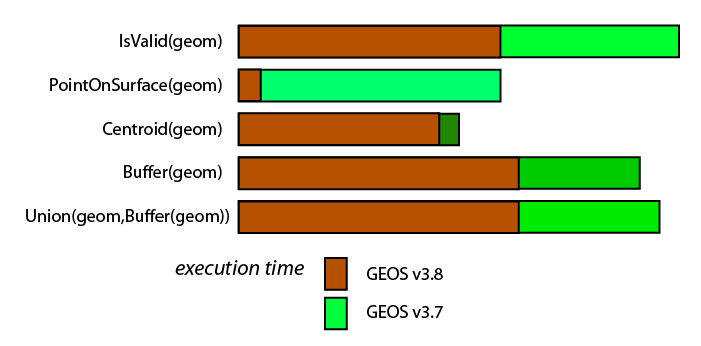
newly minted PostGIS 3 / PostgreSQL 12 / GEOS 3.8 combo
PostgreSQL 12.0 (Ubuntu 12.0-2.pgdg18.04+1) on x86_64-pc-linux-gnu Ubuntu linux 4.15 x86_64 i7-2600 CPU @ 3.40GHz shared_buffers = 4096MB work_mem=128MB PostGIS 3.0.0 r17983; Proj 4.9.3 database geom 2D POLYGON valid,simple,4326 3.1million rows * all times in milliseconds, lower is better -- GEOS 3.7.1 postgresql-12-postgis-3_3.0.0+dfsg-2~exp1.pgdg18.04+1_amd64.deb ST_IsValid(geom) 22023 21968 21976 21952 ST_PointOnSurface(geom) 53880 53668 53918 ST_Centroid(geom) 4610 4383 4384 ST_Buffer( geom,0.001) 98284 98111 ST_Union( geom, ST_Buffer(geom,0.001)) 151677 151452 -- GEOS 3.8.1 r93be2e1d; RelWithDebInfo ST_IsValid(geom) 13761 13698 13734 13672 ST_PointOnSurface(geom) 4010 3929 3943 ST_Centroid(geom) 4106 4015 4018 ST_Buffer( geom,0.001) 68152 68387 ST_Union( geom, ST_Buffer(geom,0.001)) 109546 109829
note: the graphic here shows only relative time between two runs
of the same operators, not absolute time between operators..
Compared to PostgreSQL 10 / PostGIS 2.4 / GEOS 3.6.2 only two years ago;
big evolution forward on several fronts.
* sparcels 450,000 rows, including ~1000 invalids by PostGIS definitions, mostly single ring (190MB)
* cpad19a 72,000 rows with a diverse range of area, vertice count and interior ring count (100MB)
* post_osm_bldgs 25,800 rows of recent OpenStreetmap 2D polygons marked as “building” of some kind
postgresql 10+190ubuntu0.1; postgis 2.5.2+dfsg-1~bionic1
pg_workers enabled; 4GB shared_mem
sparcels cpad osm
IsValid
3.7.1 5274 5518 311
3.8.0 2768 3669 210
3.9dev 2551 1200 172
3.10.1 800
PointOnSurface where IsValid
3.7.1 21627 11174 1189
3.8.0 4134 5526 271
3.9dev 3659 1476 269
3.10.1 1037
Centroid where IsValid
3.7.1 6352 6289 311
3.8.0 3978 5857 279
3.9dev 3383 1396 256
3.10.1 1055
Buffer where IsValid
3.7.1 21138 52019 1341
3.8.0 16711 30226 1097
3.9dev 15699 27468 1045
3.10.1 26226
Union(Buffer) where IsValid
3.7.1 36636 57707 2155
3.8.0 27883 35749 1721
3.9dev 26818 29314 1653
3.10.1 26226
* all times in milliseconds; lower is better
Hello – I am Brian M Hamlin, a Charter member of OSGeo dot org. “The OSGeo Foundation is a not-for-profit supporting Geospatial Open Source Software development, promotion and education. ”
First meta-comment : “Dear Free Open Source Developer” … this is not accurate, and badly so … This English means “your software is free (as in beer)” .. our software is not “free as in beer”, it is “free as in Freedoms” . When a large commercial company, with a history of strong actions against Open intellectual property, says “Hey developer of no-money software, why do you do this?” Do you see how this is “framing” the conversation, to show the others in a certain way?
The problem of the name of FOSS is spread across the world.. Freedom is not the same as “no-money” .
Q. Fast forward to October 2019, GitHub has just released the Octoverse 2019, in a blog. They state that “Ten million new developers joined in the last year alone, 44% more created their first repository in 2019 than 2018, and 1.3 million made their very first contribution to open source“. Furthermore, they have new features such as vulnerability alerts, and automated updates and the increased use of pull requests.
As part of a follow-up, we would like to simply ask the following question: After one year, has your perception on Microsoft’s acquisition of GitHub changed?
We encourage you to voice your opinion on this topic to us and assure that your identity is secure (anonymized). You are free to ask for your data to be withdrawn from the study.
Direct Answer to the Survey Question “How has your perception changed over one year, of the Microsoft acquisition of Github”
first, showing growth numbers alone at the top of your question, appears to show bias by you. I am not persuaded by marketing ads about growth of Github, it is an implicit invitation to “jump on the bandwagon” . For reasons listed below in detail, there is a lot of room for mistrust and doubt one year later. Github slogan “Open Source has won” is not the same as “A Microsoft company called Github has non-transparent, profit-motive control of an important platform for Open Source” !! It is trivially obvious ! Github dot com is a difficult trade-off between visibility, ease-of-use, and the misfortune of being manipulated and recorded for the sole advantage and profit of others.
Github dot com comments:
Centralization — the history of social activity across the ages is filled with a contrast between specialization and not, control or cooperation. When agriculture produced surplus, a management class was born. When armies conquered villages, a warlord was made. Human history is filled with examples of cooperative, productive people being invaded by conquerers who wish to control the surplus of others. It is not an exaggeration to say, that in the Information Age, with Internet and TCP/IP, these lessons do apply. Of course in complex systems, there are multiple effects.. common protection,or larger markets… I am not blind to some benefits here, also.. BUT Microsoft Corporation, in its “DNA” is an aggressive, for-profit conqueror, who makes no issue of taking the business of others, by cooperation or other ways.. Ask Google today what they think of Microsoft, today. However, today we discuss the point of view of the AUTHOR of original software.
Individuals are ultimately the source of invention, even in large organizations. In software development since the personal computer, individuals have a unique opportunity to invent and publish. If the individual publishes via the Internet, how do others find the results ? Of course this is challenging, but plurality grows with local effects.. Japanese language authors, special needs like a diabetic patient, detective stories in English .. lots of example where local authors can publish to certain audiences, but also have large groups via markets and communications… Somewhere in this story, the forces change to the scale of society and the world.. especially in military competition, in electronics themselves (since they have no language, only circuits), and “security” which I will not try to describe..
Social-scale competition creates an endless need for collecting the works of others, for advantage. Did you know that Github dot com was hired by the United States Pentagon, to create constant reporting on relevant publications and activity privately ? (more on this kind of thing in a later section).
I show that local publication, or market segment publication, supports diversity of opinion, of cultural expression, and trade opportunity to others, when the products are ready. Individual authors are the origin of invention, even in large settings, and benefit from some mix of localization and markets. Extreme centralization has a negative history across the ages. An endless hunger for the work of others drives some un-balanced market activity, and can be psychologically associated with the role of raiders, plunderers and slave owning in extreme cases, which is obviously profitable. The rules of law and moral drivers put some balance on extreme aggressive activity, over time.
Vendor Lock-In with Features — In the normal course of teamwork on Open software, especially software with a long life, the tickets, comments and collaboration features become very important. Microsoft has a long history of using features on top of standards to lock in customers in a “soft” way. Github shows all of the qualities to fit this kind of strategy. Hundreds of Linux software developers over time, led by Linus Torvalds, wrote the difficult and precise GIT software, but it is hard to use. Github dot com adds a user interface, and facilitates common GIT patterns via a good-looking, straightforward web interface. The value-add to GIT is obvious, which contributed strongly to success at Github. Microsoft paid to own the right to control the feature set development, and has shown over decades that they use this control for vendor lock-in.
Transparency — Computer systems have a unique capacity to make lasting records of vast amounts of information, report on that information, and transmit that information. “Data is the new Oil” is a saying that has been repeated in the recent Internet times. When individuals and teams make progress on their challenging new technology, their time and effort is in the invention. Yet a common computer system can record the efforts and results of the activity quietly, report on it, and transmit it, without the knowledge of the users. It is practically a “one-way mirror”. Operators of the common system can see ALL the activity of the users, yet users may not see the activity of others. Who owns this reporting capacity ? What restrictions are in place for privacy ? What kinds of records are kept, on which teams ? We are in new territory. Ask the Board of Directors of a Stock Market, if there is advantage to reporting on the sum total of all trading in their system. It insults the intelligence of authors, to suggest that smart people cannot know that there is value being created by reporting on their activity. There is no gurantee of fairness and rights without oversight. Microsoft Corporation was repeatedly convicted of unfair trade practices, while the founder Bill Gates displayed his wealth for more than twenty years. Despite promises, ads and financial contributions to Universities, there is no way to know what is being done without Transparency. Since it is effectively not possible to know all the parts of such a large and active system, it is very, very difficult to see fairness over time with a centralized, opaque system owned by a competitive corporation.
Records on Others as a Profit Source — if Data is the New Oil, then selling that data is obvious. As in the example above, Github earned contract money from the USA Pentagon by creating high-level, consistent reporting privately for their wealthy, competitive client. Why does the individual and team put their core content on a common site, and derive no profit (money) from the sale of reports on it ? The distribution of profits in FOSS eco-system is deeply debated right now. It is obvious that many lack the de-facto ability to collect money from their software, although every author needs to sleep somewhere, and eat food. I am writing to you from the San Francisco Bay Area, which is heavily impacted by unequal distribution of money.
Records on Others as a Surveillance Source — common security is a balance, and a moving target. From the point of view of law-enforcement, there is no end to the details they may want (“need”) on the activity of individuals or teams, over time. But the rule of law (supposedly) sets a balance between this security record keeping, and the actions of an individual as they choose. Moving to budgets, in fact, in a large society, security is constantly funded, while authorship is sporadic and un-predictable. Over time, constant budgets have a survival benefit, while authors may starve or take forced choices during low productivity. Very large companies are attracted to constant revenue over sporadic invention. This creates “perverse incentives” in markets to create new products for security, instead of supporting invention by authors.
Psychologically and behaviorally, a predator mode is part of human nature, and has a rough history associated with it. Surveillance of the activity of others, routinely exceeds rational need in nations around the world. Add to this the “other” of activity of a different group, tribe, ideology, market or similar, and the drives to create surveillance quickly escalate. Like other social expressions, the ones who really are purposefully dangerous, are much more difficult to detect and monitor, than those who are expressing healthy rebellion, trying new things, or learning by acting out in some developmental way.
I have shown that there is an extreme and unhealthy tendency to create surveillance records for sale to constantly funded security systems in a large society. Github can be used in this way, sometimes beyond the real bounds of software development.
Motivations Matter — Just as a corporation seeking profitable control is seen as “natural” , so the drive of authors to invent, express, and solve problems is also natural. The motivation of a company the size of Microsoft, with a system as active as Github, is not possible to summarize in single sentences. However, it is safe to say that the motivations of authors tend to problem solving for profit and also for non-profit, while the motivations of a corporation tend toward capturing and controlling profit in money terms. As a contributor to “Free as in Freedom” software, I will absolutely defend the rights and interests of authors first.
![]()
On the OSGeo Japan -discuss mailing list regarding FOSS4G 2019 KOBE.KANSAI :
今年は、Geo-AIのテーマにマッチした、ディープラーニングの勉強が初歩から体験できるコースが2つあります!
translation: this year, there are two courses that match the theme of Geo-AI, where you can experience deep learning from the beginning!
An OSGeo Japan wiki page says: 今年のテーマは「Geo-AI」です。
translation: this year’s theme is “Geo-AI”.
Geo-AI a closer look – “geo” is easy, what about AI?
a working definition of AI*:
Artificial Intelligence is the theory and development of computer systems able to perform tasks which previously required human intelligence. AI is a broad field, of which Machine Learning ML is a sub-category.
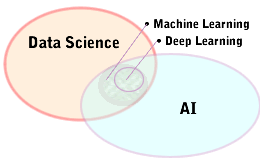
Data Science overlaps Artificial Intelligence, Machine Learning exists in that overlap.
When people speak about Machine Learning these days, they are often speaking of Deep Learning, a subset of Artificial Neural Networks NN.. networks consisting of connected, simple processors called “neurons” wikipedia -LINK-nn -LINK-dl This blog post -LINK- describes NN training methods, including “weakly supervised” and “transfer learning.”
Since 2009, supervised deep NN‘s have won many awards in international pattern recognition competitions, achieving better-than-human results in some limited domains. — Schmidhuber 2015 Survey of Deep Learning
Deep Learning is especially effective on data sets like images and sound, and typically improve with the amount of training data available. Deep Learning is not new, but what is new are the volumes of available labelled training data, and the capacity to compute on them. Many Deep Learning programming libraries are in Python, and many libraries run natively on a GPU. -LINK-sklearn -LINK-pyTorch
Data Science uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data. wikipedia -LINK-ds
Machine Learning as a subject, is the study and application of algorithms and statistical models that computers use to execute some tasks without explicit instruction; sometimes known as predictive analytics. -LINK-ml
* ai-and-the-global-economy-mark-carney-2018
OSGeoLive v13 (o13) -LINK-
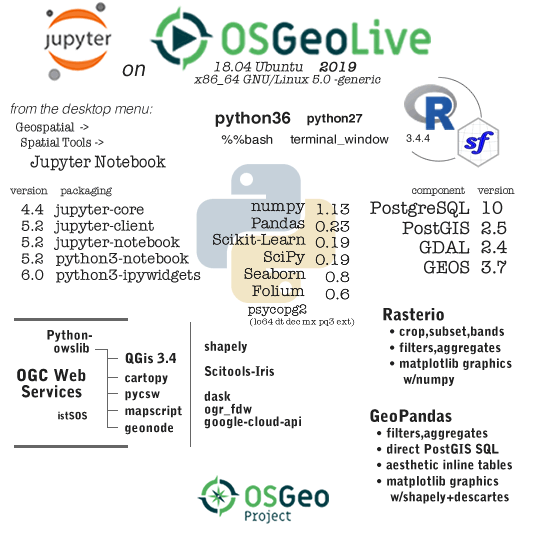
the Jupyter eco-system installed and integrated on osgeolive13
this post is an edited, public version of a DRAFT internal discussion
Preamble
This blog post is intended to bring together topics, facts, considerations and other useful information pertaining to upcoming licensing decisions on full-stack software. It is assumed that all license decisions must be made prior to hand-off of the works to the contract originator. All license decisions must exist in writing.
As noted below, some person or entity must have signature authority to enact these license decisions. Subsequently in the project life cycle, it is recommended that a project steering committee be formed with the authority to make or reject further changes.
note:
· not all components must have the same license
· dual licensing of GPL and non-GPL is possible (more on this later)
· this is a data-driven project – data (a lot) is the origin and outputs data sets require their own licenses in any event because GPL and other OSS licenses apply to source code, not data
· the means to transform data into a base load, into a DOCUMENT, and read the outputs are code, and must be licensed
The deliverable to the contract originator is “—-” (confirm)
Major software initiatives using an Open Source model have flourished in an unprecedented success over the last 15 years, with names like GNU, Linux, BSD Unix, Apache and Mozilla. If the ability of software developers to contribute to common source code, and to form functional communities focused on continuous improvements to their projects is the engine, then the application of standardized licensing to source code (and therefore to new contributions) is what keeps that engine on track.
Open Source by Definition
redistribution is permitted
source code is available
licensee may make derived works
see OSI
copyright is held by the party who commissioned the work
passing through the contractor to the contract originator
Distribution Rights
– who can copy the code (possession)
– who can deploy the code (run an instance of the software)
– what rights do users have with the copier/deployer (right to obtain source)
Modification Rights
– who can modify this code
– who can distribute their modifications, under what terms?
– what responsibilities do distributors of modifications have ?
Generational Limitation
Once a copy of the source code has been modified, what limitations apply to the license for distributed, changed copies? Specifically, can code be changed from an open license to a less-open license (“go closed”), or not? Must the brand / origin be displayed ? Is a party that modifies the project required to publish their changes ?
The licensor asserts explicitly or implicitly, that they have the right to license this source code
licensor states warrenties and disclaimers
warranty of merchantability
warranty of fitness for a particular purpose
warranty against infringement
either grants protection against patent infringement or not
licensor explicitly states rights granted to the licensee
including what grants the licensee may make to further licensees
We do not want to define a custom license – there are enough to choose from!
Google on Licenses Blog · OSI The Open Source Initiative
Mozilla Public License – http://www.mozilla.org/MPL/
“The MPL fills a useful space in the spectrum of free and open source software licenses, sitting between the Apache license, which does not require modifications to be shared, and the GNU family of licenses, which requires modifications to be shared under a much broader set of circumstances than the MPL.” – http://www.mozilla.org/MPL/2.0/FAQ.html
(from Wikipedia)
… The MPL allows covered source code to be mixed with other
files under a different, even proprietary license. However, code files licensed under
the MPL must remain under the MPL and freely available in source form. This makes
the MPL a compromise between the MIT or BSD licenses, which permit all derived works
to be relicensed as proprietary, and the GPL, which requires the whole of a derived work, even new components, to remain under the GPL. By allowing proprietary modules in derived projects while requiring core files to remain open source, the MPL is designed to motivate both businesses and the open-source community to help develop core software.
The rights granted by the Mozilla Public License are primarily defined as passing from “contributers,” who create or modify source code, to the licensee. In the absence of patents, MPL-licensed code can be freely used, altered, and redistributed. Versions with patented code can still be used, transferred, and even sold, but cannot be altered withoutspecial permission. In addition, the MPL does not grant the licensee any rights to a contributor’s trademarks.
To fulfill the terms of the MPL, the licensee must meet certain “responsibilities,”
mostly concerning the distribution of licensed software. The licensee must ensure access to or provide all source code files covered by the MPL, even if the software is offered as an executable or combined with other code under a proprietary license. The one exception to covered files remaining under the MPL occurs when they are combined with code under the GPL, Lesser GPL (LGPL), or Affero GPL (AGPL). In this case, the creator of the combined software can choose to provide the entire work under the stricter GPL-based licenses.
The MPL has been approved as both a free software license (albeit one with a
weak copyleft) by the Free Software Foundation[3] and an open-source software license by the Open Source Initiative.[4]
[3] “Mozilla Public License (MPL) version 2.0”. Various Licenses and Comments about Them.
Free Software Foundation. Retrieved 2012-01-03.
[4] “Open Source Licenses”. Open Source Initiative. Retrieved 2012-01-07.
MIT, BSD, Apache Licenses
“… allow code to be used in proprietary software and do not require that open
source versions of the code be distributed. Code created under these licenses, or
derived from such code, may go ‘closed’ and developments can be made under that
proprietary license, which are lost to the open source community.
”
It is worth considering the Apache v2 license, or the Academic Free License here, since they are more recent that the original BSD and MIT/X, and contain some refinements
Non-lawyer Brian says :
These licenses DO NOT prevent a competitor to FIRM from taking a complete project, making source code changes that are not published, and advertising the product as their own, as long as certain notices are retained within the code.
“In short, research-style licenses, like the BSD and MIT Licenses, are ideal for
situations in which you want wide deployment of your ideas and do not care whether
this results in open source software or proprietary software.”
Apache Software License (ASL)
see ArsTechnica on Google GPL ASL HERE
“ASL, which is widely used in the open-source software community and has been
approved by the Open Source Initiative, is a permissive license that is conducive to
commercial development and proprietary redistribution. Code that is distributed
under the ASL and other permissive licenses can be integrated into closed-source
proprietary products and redistributed under a broad variety of other terms.
Unlike permissive open-source licenses, “copyleft” licenses (such as the GPL)
generally impose restrictions on redistribution of code in order to ensure that
modifications and derivatives are kept open and distributed under similar terms.
Permissive licenses like the ASL and BSD license are preferred by many companies
because such licenses make it possible to use open-source software code without
having to turn proprietary enhancements back over to the open source software
community. These licenses encourage commercial adoption of open-source software
because they make it possible for companies to profit from investing in enhancements
made to existing open-source software solutions.”
OSI 4
The license must explicitly permit distribution of software built from modified
source code. The license may require derived works to carry a different name or
version number from the original software.
GPL, GPLv2, LGPL
These licenses are the most prescriptive on the rights of those that modify and
adopt the project software.
GPL
Software can be distributed and modified without additional permission of the licensor. This imposes a mirror-image restriction on the licensee: while the licensee has free access to the licensed work, the licensee must distribute any derivative works subject to the same limitations and restrictions as the licensed work. Derivative works must be licensed under the GPL and be subject to all of its conditions.
see GNU Software -LINK-
GPLv3
Introduced in 2007 – GPL Definitions -LINK- An essay discusses the differences in GPLv3. -LINK- The primary goal appears to prevent certain kinds of modification (“Tivoization”)
Brian says: I do not believe that any open source license can restrict the use cases of the software, including commercial use. So there is no such thing as “GPLv3 non-commercial” see-LINK- ; “No OSI-certified Open Source license (or FSF-approved Free Software license) will restrict commercial use…” David Thornley, 30dec10
GPLv2+ is modified v2 to be compatible with v3
LGPL
A key difference in the LGPL is that is does not restrict the ability of a library to “link” to othe libraries.. (referring to compiled-code architecture) The GPL wording is such that a GPL licensed code project cannot be linked to non-GPL code, but an LGPL library can.. Stallman discusses an implication of this here
see GNU Why not LGPL -LINK-
Python Software Foundation License
The license for python, itself. -LINK-
from wikipedia:
The Python Software Foundation License (PSFL) is a BSD-style, permissive free software license which is compatible with the GNU General Public License (GPL). Its primary use is for distribution of the Python project software. Unlike the GPL the Python license is not a copyleft license, and allows modifications to the source code, as well as the construction of derivative works, without making the code open-source. The PSFL is listed as approved on both FSF’s approved licenses list, and OSI’s approved licenses list.
Source code written in python can not be hidden while it is running. -LINK-
This topic remains contentious and is still evolving rapidly. Drivers of change include new technology, new social norms and new markets.
Creative Commons
A quick web tool to assist in choosing a license -LINK-
Example — given that modifications are permissible as long as they are published, and
if commerical use of the datasets are permissable
Creative Commons Attribution-ShareAlike 3.0 United States License -LINK-
or, if commercial use of the datasets is not permissable
Creative Commons Attribution-NonCommercial-ShareAlike 3.0 United States License -LINK-
An introduction to an open data in general HERE
Open Data Commons.org
The Open Data Commons appears to be expanding -LINK-. Their
license appears to be an approximation of the GPL for data. HERE
GUI
The sketching GUI will immediately be identified by some as “the product.”
Internal architecture and components are not visible to those without knowledge of software tech.
However, the GUI as written is only one possible interface to the underlying engines, by design.
GUI includes some data, for example, visual style definitions in Geoserver, but does not include base-load and DOCUMENT definitions.
Some GUI-specific data can be repurposed in other implementations e.g. geoserver style definitions.
Framework
The technology mix used to initiate, process and retrieve. The backbone of the project, to which all parts are connected.
DOCUMENTS are data in a certain form. Currently the only practical way to create DOCUMENTS is through the GUI, but a DOCUMENT in the defined form is NOT part of the GUI, but part of the framework.
Engines
Engines are discrete components, and may carry a separate license. An example is a specialized CALC engine that is re-written for performance, or to express a different model. Engines may perform only on base data, only on DOCUMENT data, or both.
Base Load Data
The ability to load base data – “base load scripts” must have a license
The data products must have a license
Documentation
Documentation is a “value add” and can be considered its own component. Docs can be in the form of “help” with context, often embedded, or as a book, to be read, studied, referred to, etc..
Components
Each of the above are written in programming languages which are different. The most stark example is the Web GUI, written in Javascript and the Django python framework.
The Framework is the collection of python and Postgresql/PostGIS SQL.
Engines are particular, discrete expressions of models,
currently in python and SQL but could be written in even higher performance code.
Base Load scripts.. the ability to take public and private data sets, well defined, and transform them into the particular database tables operated upon by the Framework.
Brian’s Thoughts on “Why”
there are several axiis upon which to measure characteristics and likely trajectories of OSS. The following names some of those and asks, what are the goals of the project along these axiis ?
What are the goals of FIRM? It may be said that “if you want to hack, try it out yourself, if you want to initiate a paid study, contact FIRM”
Community versus Poker
Poker is a game where all participants are known to each other as fighting for their own best interests at all times. Paradoxically it does form communities around the activities, but the goals are clearly self-serving. There is mostly “poker” in business relationships. Community on the other hand, implies considerations of group benefits at all times, perhaps expectations of individuals to take losses for the benefit of the whole.
Local government is allegedly a community office. Particularly high quality or enabling software is known to draw community. Science is sometimes termed community, although paradoxically, science is often highly competitive and therfore encourages self-serving decisions.
This project spreads both technical capacity, and brand. Control of the brand, with implied quality, is a crucial consideration in the permissiveness of the modification license. The license may state that derived works MUST NOT carry the original brand, or MUST, there is an argument for either.
Speed of Adoption, Size of Adoption
How many organizations might use this tool set, now or in a few years from now?
At what rates are first contact, first trial and first real usage desirable
or even possible ?
There are well-understood characteristics of the patterns of new product adoption
see Wikipedia on Diffusion of Innovation HERE
Encourage and enable adoption versus hold back powerful competitors
In a networked environment, and a high quality product of specialized interest,
the dynamics change quite a bit. Technical consulting can be very difficult
endeavor, and for the successful, holds importance and money. While keeping a goal of
new comers enabled by tech to do great analysis, the fact is that a small number of
powerful technical consulting groups may find this package useful to compete with the
others, to provide services to those unable or uninterested in doing it themselves.
This package is so enabling, that it could be said to further the state of the art
in the field.
Data Driven Analysis
this environment is data driven, that is, extensive and diverse data is required to
start, and the output is largely data. Quality and quantity of data is immediately an
issue. Is the goal to spread the technology widely, while playing poker with the data?
Is it to distribute the data widely, and play poker with the client relationships ?
There is an unending desire by knowledgeable parties for data, both inputs and outputs. The work to clean, organize and report the data is enabled by the software, but it is not free – resources must come from somewhere.. The Federal, State and County governments are huge sources of raw data, but it is not enough.
What is the desired net effect of the release of this project with respect to the data, and the ability to produce it, integrate new sources, produce new reports? This topic is almost as large as the Framework and GUI itself – consider that the Framework and GUI are not easily written, but far fewer parties would have interest in modifications; while the data is of interest to virtually all who would be interested in this project.
End Notes
The decision to mark software work products with an Open Source license, and how to handle data associated with the project and its use, is complicated and deserves attention. Here we have reviewed a collection of the most popular Open Source licenses. Data must be licensed separately from code, and some attention is shown to emerging data licenses. The motivation to write this is that a full-stack software project is considered for licensing decisions. Customers, community motivations and strategy are briefly discussed. With this short post, several large and different approaches can be seen, compared and contrasted.
references
https://code.gov/about/overview/introduction
EU eGovernment Services OSS-procurement-guideline HERE
UM FOSS GIS University of Massachusetts, Amherst 2007