Newly released PostGIS 2.1 rocks.. How can I install it on a fresh Debian 7 ‘wheezy’ to try it out?
Here is a recipe that worked for me:
—
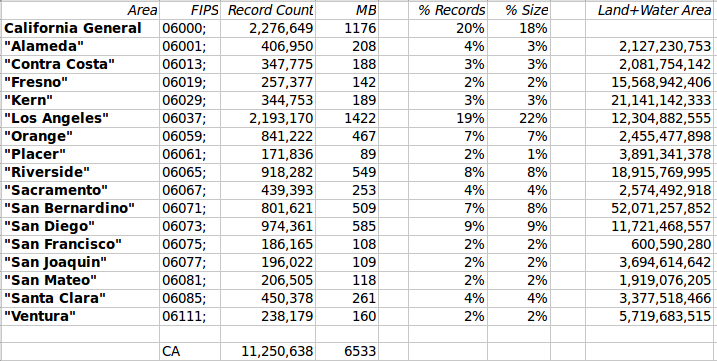
Final Results
debian_version 7.1
PostgreSQL 9.1.9 on x86_64-unknown-linux-gnu
-----------------------------------------------
myrole=# select postgis_full_version();
POSTGIS="2.1.1dev r11823"
GEOS="3.4.2dev-CAPI-1.8.0 r3897"
PROJ="Rel. 4.7.1, 23 September 2009"
GDAL="GDAL 1.11dev, released 2013/04/13"
LIBXML="2.8.0"
LIBJSON="UNKNOWN"
RASTER
—
Shell Steps
df -h
sudo apt-get update
mkdir srcs_local
cd srcs_local
sudo apt-get install build-essential flex autoconf libtool gdb gfortran subversion htop
sudo apt-get install postgresql-plpython-9.1 postgresql-server-dev-all python-psycopg2
sudo apt-get install xsltproc libproj-dev python2.7-dev
## GEOS
svn co http://svn.osgeo.org/geos/branches/3.4 geos_34_branch
cd geos_34_branch/
./autogen.sh
./configure
make -j6
sudo make install
ls -l /usr/local/lib
cd ..
## GDAL
sudo apt-get install libcurl4-openssl-dev libgcrypt11-doc
sudo apt-get install libpcre3-dev libjson0-dev libxerces-c-dev libexpat1-dev libxml2-dev
sudo apt-get install libkml-dev
svn co http://svn.osgeo.org/gdal/trunk gdal_trunk
cd gdal_trunk/gdal
./autogen
./configure --with-python --with-curl
make -j6
sudo make install
sudo ldconfig # for good luck
cd ../autotest/
##-- test out the new gdal
python run_all.py
## PostGIS
cd ../..
svn co http://svn.osgeo.org/postgis/branches/2.1 postgis_21_branch
cd postgis_21_branch/
./autogen.sh
./configure
make -j4
sudo make install
sudo ldconfig # for good luck
sudo su - postgres
# psql
> create role myrole superuser createdb login;
exit ## out of linux user postgres shell
createdb myrole
psql
sudo service postgresql restart
—
The libraries in /usr/local/lib are symbolically linked. It ends up looking like this:
----------------------
libgdal.a
libgdal.la
libgdal.so -> libgdal.so.1.17.0
libgdal.so.1 -> libgdal.so.1.17.0
libgdal.so.1.17.0
libgeos-3.4.2dev.so
libgeos.a
libgeos_c.a
libgeos_c.la
libgeos_c.so -> libgeos_c.so.1.8.0
libgeos_c.so.1 -> libgeos_c.so.1.8.0
libgeos_c.so.1.8.0
libgeos.la
libgeos.so -> libgeos-3.4.2dev.so
liblwgeom-2.1.1dev.so
liblwgeom.a
liblwgeom.la
liblwgeom.so -> liblwgeom-2.1.1dev.so