Some problems in PostGIS are naturally parallelizable. Many problems involving a grid as a base or reference data set fall into this category; when each grid cell is visited and some operation is done there, each grid cell is uniquely referenced in its own set of calculations, and invariant, then it is likely that the problem is naturally parallelizable. If the computation could be done on more than one cell at a time, so much the better.
Some problems in PostGIS are naturally parallelizable. Many problems involving a grid as a base or reference data set fall into this category; when each grid cell is visited and some operation is done there, each grid cell is uniquely referenced in its own set of calculations, and invariant, then it is likely that the problem is naturally parallelizable. If the computation could be done on more than one cell at a time, so much the better.
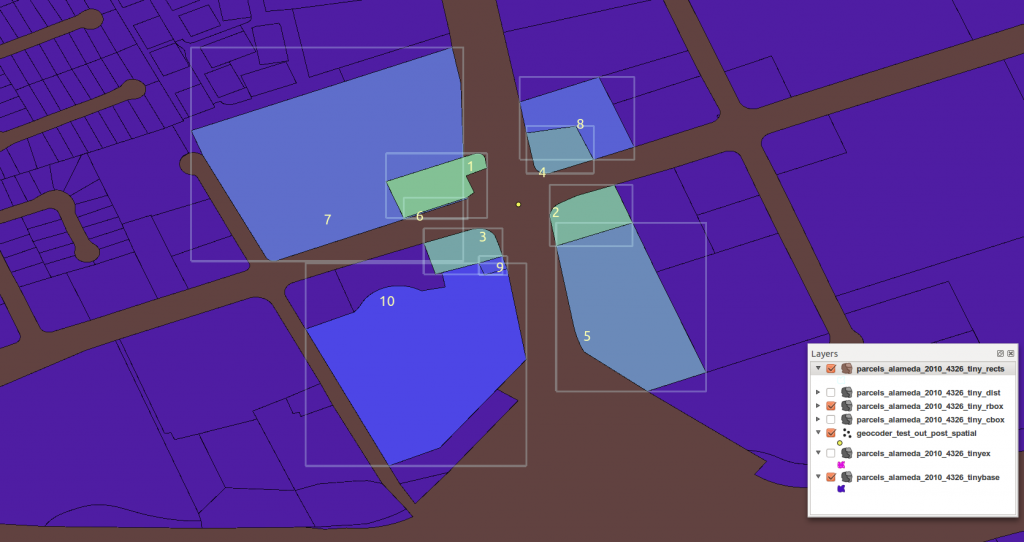
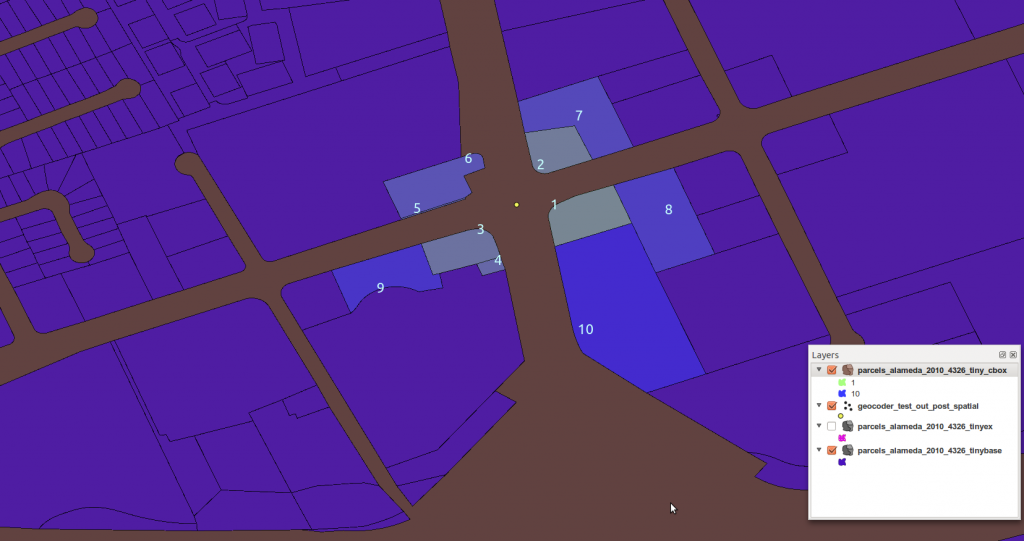
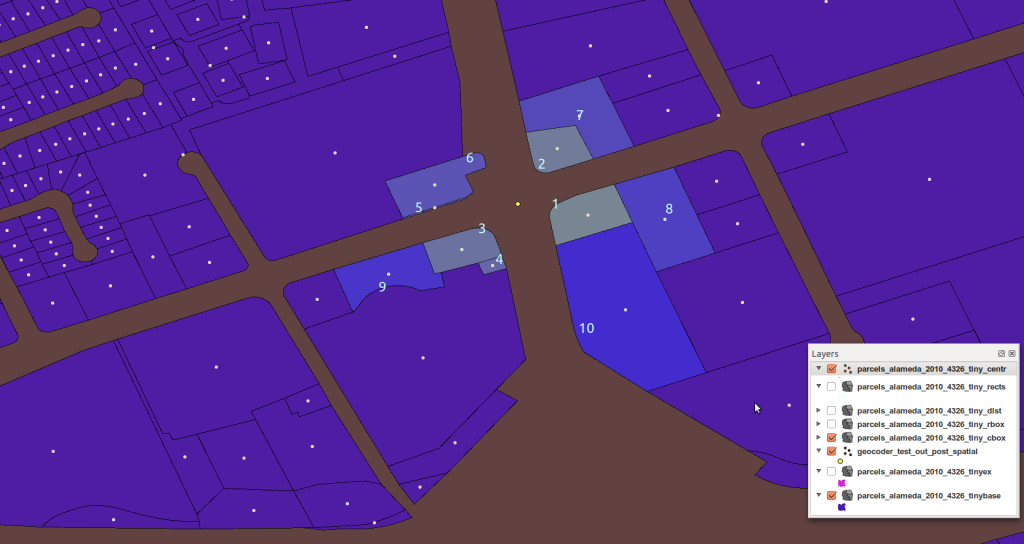
Search Radii
There are many variations on this problem, and many approaches to solving any given one. Consider the following: a database table representing a regular grid is “loaded” directly with data per cell. The table definition might look like:
create table data_buffers_variable (
id150 integer PRIMARY KEY,
prod_mil_meters double precision,
wkb_geometry geometry,
acres_red_total double precision,
acres_yellow_total double precision,
qt1 double precision,
qt2 double precision,
qt3 double precision
)
Each cell will be visited in turn, and reference a number that is a distance prod_mil_meters, which after conversion to units in the current projection, is used as a radius. The calculation is then to collect all cells within the determined radius, and sum three quantities.. qt1_total, qt2_total, qt3_total. Here is a query on a single cell cur_id in a radius of search_radius, and a self-join like so:
SELECT
b.id150, search_radius, b.wkb_geometry,
sum(r.qt1) as qt1_total,
sum(r.qt2) as qt2_total,
sum(r.qt3) as qt3_total
FROM
data_buffers_variable b
INNER JOIN data_buffers_variable r
ON ST_DWithin(b.wkb_geometry,r.wkb_geometry, search_radius) AND
b.id150 = cur_id
GROUP BY b.id150, b.wkb_geometry
Many Hands Make Light Work
We might define a function call in PostgreSQL as follows:
CREATE OR REPLACE FUNCTION get_buffered_vals_out( in_id_grid int, in_distance float, in_geom geometry, OUT id_grid int, OUT search_distance float, OUT wkb_geometry geometry, OUT qt1_total float, OUT qt2_total float, OUT qt3_total float ) AS $$ select $1 as id_grid, $2 as search_distance, $3 as wkb_geometry, sum(r.qt1) as qt1_total, sum(r.qt2) as qt2_total, sum(r.qt3) as qt3_total FROM data_buffers_variable r WHERE st_dwithin( $3, r.wkb_geometry, $2); $$ COST 10000 language SQL STABLE strict;
Now to run this in a parallel fashion. As is detailed in this post, do the following in python: decide on a number of threads to execute, divide the work into buckets with an upper and lower id_grid as bounds, define the basic unit of work as a threading.Thread subclass, and pass a parameter dict into a thread_queue for each thread. Each threaded unit of work will visit each cell within its bounds, call get_buffered_vals_out() and store the results.
note: although it looks more impressive, double precision is in fact a synonym for float in postgres
The syntax for INSERTing the result of a function call like that into another table in one statement can be rather challenging. Here is some useful starter syntax:
select (f).* from (
select get_buffered_vals_out( ogc_fid, dist, wkb_geometry) as f
from data_buffers_variable
where ogc_fid >= 1656690 and ogc_fid < = 1656690
offset 0) s;
Why the offset 0 ?!? Its is supposedly a no-op, yet in one test, the runtime is 6x faster with it than without it. More answers yield more questions…
addendum-
whunt how do you reference a value from the select clause in your where clause? RhodiumToad whunt: you don't whunt as in: SELECT my_func(bar) as baz from foo where baz is not null; RhodiumToad whunt: not allowed per spec, though you can add another nesting level whunt i could do it with a with RhodiumToad whunt: select * from (select myfunc(...) as baz from ...) s where baz is not null; RhodiumToad whunt: note, that'll often call the function twice; to prevent that, add offset 0 just before the ) RhodiumToad whunt: i.e. select * from (select ... offset 0) s where ... xocolatl RhodiumToad: the offset 0 trick is something I think needs improvement we shouldn't have to do that RhodiumToad I agree RhodiumToad but it's not at all trivial xocolatl oh, I don't doubt whunt why does the function get run twice? RhodiumToad whunt: because the planner will flatten out the subselect in most cases, so it's equivalent to doing whunt i imagine the inner query executes the function and creates a new table that the outter query queries whunt oh RhodiumToad select myfunc(...) from ... where myfunc(...) is not null; whunt lol - that's exactly what i wanted to avoid xocolatl whunt: then use the offset 0 trick RhodiumToad the offset 0 is a general technique to nobble the planner and stop it from flattening subqueries